Algorithms
- On-Policy Algorithms
- most basic, entry level, old
- Vanilla Policy Gradient
- cannot reuse old data → weaker on sample efficiency
- algos optimize for policy performance
- Trade off sample efficiency in favor of stability
- TRPO and PPO
- Off-Policy Algos
- younger, connected to Q learnging algos, learns Q-funciton and a policy which are updated to improve each other
- Can use old data very efficiently
- they get this benefit through Bellman’s equations for optimality
- No guarantee that doing a good job of satisfying bellman’s equations leads to having great policy performance.
- Empirically one can get good performance, and with such a great sample efficiency is wonderful, but the absence of guarantees makes algos in this class brittle and unstable
- Deep Deterministic Policy Gradients DDPG foundational
- TD3 and SAC are decendents of DDPG
Introduction to Reinforced Learning
Part 1: Key Concepts in RL
Key Concepts and Terminology
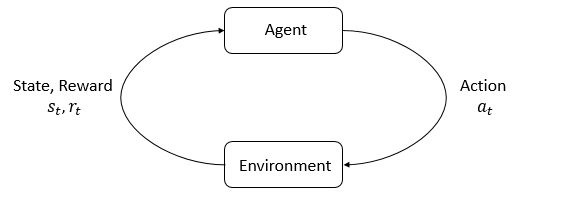 Main characters of RL
Main characters of RL
- Agent - decides what actions to take, and perceives a reward signal from the environment (number saying how good or bad). GOAL maximize cumulative reward, called return.
- Environment - world that the agent lives in and interacts with
State - complete description of the state of the world. There is no hidden information about the world which is not in the state Observation - partial description of a state, which may omit information
Fully Observed- when the agent observes the complete state of the environment Partially observed - when the agent sees a partial observation
Action Spaces - the set of all valid actions in a given environment
- Discrete actions spaces, finite number of moves are available
- Continuous action spaces → normally real-valued vectors
definition of stochastic - refers to a process or model that involves some level of randomness or unpredictability.
Policy - rule used by an agent to decide what actions to take
-
Deterministic Policy () ⇒
-
- is actions to take
- implies deterministic relationship
- given a particular state, the agent will always take the same action, there is no randomness. Given state it will always take
-
-
Stochastic Policy () -
- : This represents the action taken by the agent at time ( t ).
- : This symbol means “sampled from.” It denotes that the action ( a_t ) is drawn from the probability distribution that follows.
- implies there is a range of actions that could be taken
- : This is the policy, which, in the context of a stochastic policy, is a probability distribution over actions.
- denotes conditional probability. READ as given. Given S you have a
- : This is the probability distribution over actions given the current state ( s_t ) at time . The dot in the parentheses is a placeholder for the action space. It indicates that the policy provides probabilities for all possible actions that can be taken in state .
- When you see , this is read as “the probability of taking action given the state ” under the policy .
- : This is the state of the environment or the agent at time ( t ).
-
Types of Stochastic Policies
- Categorical Policies - discrete action space
- A categorical policy is like a classifier over discrete actions. You build the neural network for a categorical policy the same way you would for a classifier: the input is the observation, followed by some number of layers (possibly convolutional or densely-connected, depending on the kind of input), and then you have one final linear layer that gives you logits for each action, followed by a softmax to convert the logits into probabilities.
- Diagonal Gaussian Policies - have a neural network that maps observations to mean actions with added randomness via a vector of standard deviations (diagonal covariance matrix which because it is diagonal all of the variables are independent and all of the “covariance” are 0s) element wise producted with randomness
- The added randomness with standard deviation can be interpretted as the models uncertainity over it’s choice. This uncertainity can be fixed, or it can be generated by the neural network so that it would have different amounts of uncertainty per input.
- Categorical Policies - discrete action space
-
Parameterized Policies - policies whose outputs are computable functions that depend on a set of parameters (weights and biases of a neural network) which we can adjust to change the behavior via some optimization algoritm
- Parameters of these policies are or , then with a subscript to show the connection
- Parameters of these policies are or , then with a subscript to show the connection
Trajectories
- A trajectory is a sequence of states and actions
- is randomly sampled from the start-state distribution,
- acts a placeholder for a variable.
State Transitions - what happens to the world between state at time t and the state at t+1 is defined by the laws of the environment (frequently called episodes or rollouts.
- Deterministic World Environment:
- Stochastic:
- We are sampling the next state () from the probability distribution given the state and the action
- - stands for state transition probability, it is the probability of ending up in a particular next state
Reward and Return
Reward Function takes in the state of the environment, actions, and environment after action.
- Also simplified as only dependant on the state of the environment or state-action pari
- Types of Return
- finite-horizon undiscounted return -
- which is just a sum of rewards in a fixed window of steps
- infinite-horizon discounted return -
- which is the sum of all rewards ever obtained by the agent, but discounted by how far off in the future they’re obtained. The goal of the agent is to maximize the notion of cumulative reward over a trajectory (a series of state-action pairs)
- finite-horizon undiscounted return -
Central Problem for RL
The central problem for reinforcement learning is maximizing cumulative reward through a optimal policy
We can formulate this by . Where is the expected return across all probabilities of outcomes and their reward. Basically how the reward this policy would have across the total distribution of cases and their reward.
-
- - stands for state transition probability, it is the probability of ending up in a particular next state
Expected Return
- is the return of the trajectory , which is the total accumulated rewqrd from the following trajectory
- the expected return is which is the average return that you would expect to get if you were to follow policy over all trajectories
- It is calculated as the integral, for each trajectory find the probability of that trajectory occurring times the return of that trajectory
Value Functions
Value functions are used when you need to know the value (expected return) of a state or state-action pair,
- On-Policy Value Function - gives the expected return if you start in state and always act according to the policy
-
- Calculates the expected sum of the rewards an agent would receive given state and follows policy for the trajectory.
- This equation is supposed to predict how good a particular state would be under a policy.
- is an expectation operator, and it denotes the expected value of a random variable
- means the trajectories (the list of state and action pairs) sampled according to the policy
- means that it is an average over all trajectories starting with
- denotes that it is given starting state … “Given start state ”
-
- On-Policy Action-Value Function - which gives the expected return if you start with state , and take an action (which may have not come from the policy), then forever refer to the policy \pi for the following acitons
-
- Calculates the expected sum of the rewards an agent would recieve given a starting action of and state of while following policy for all future actions
-
- Optimal Value Function which gives you the expected return if you start in state and act with the optimal policy
- Optimal Action-Value Function - which given a starting state and action, the agent will always act from the optimal policy
Part 2: Kinds of RL Algorithms

Model of the environment - a function which predicts state transitions and rewards If we have a model we can use it to plan by thinking ahead, seeing what would happen for a range of possible choices. Agents can then distill the results from planning ahead into a learned policy. The main downside of having a model is that a model that perfectly reflects the real world rarely exists. If the agent wants to use a model, it has to learn the model purely from experience